Alle Fachrichtungen
- Zum Verfassen von Kommentaren bitte anmelden.
U1: Allgemeine Geschäftsbedingungen
- Zum Verfassen von Kommentaren bitte anmelden.
Allgemeine Geschäftsbedingungen
Definition
Allgemeine Geschäftsbedingungen sind alle für eine Vielzahl von Verträgen vorformulierten Vertragsbedingungen, die eine Vertragspartei (Verwender) der anderen Partei (Vertragspartner) bei Abschluss eines Vertrags stellt. [§ 305 BGB Abs. 1]
Verwendung
AGB sind nicht gesetzlich vorgeschrieben, in der Praxis werden sie dort verwendet, wo eine Vielzahl von Verträgen zustandekommen, Standardbedingungen Sinn machen, z. B. Online Shop, Mietverträge, Kaufverträge, Bauverträge, etc..
Vorteile für den Verwender
- - Einheitlichkeit aller Verträge
- - Juristische Sicherheit bei Vertragsproblemen
- - Regelungen, die zugunsten des Verwenders ausgelegt werden
- - Neutralisierung der AGB des Vertragspartners (Bsp.: AGB eines Kleinunternehmers kann die AGB eines Großkonzern außer Kraft setzen)
Anwendbarkeit
AGB sind nur Bestandteil eines Vertrages, wenn
- - der Anwender ausdrücklich vor Vertragsabschluss darauf hingewiesen hat,und dem Vertragspartner eine zumutbare Möglichkeit verschafft vom Inhalt Kenntnis zu nehmen (Aushang, Satz mit Link zu den AGB, etc.)
- - der Vertragspartner den Bedingungen ausdrücklich zustimmt,
- - den gesetzlichen Regelungen zu AGB entsprechen => Schutz des Verbrauchers vor Risikoabwälzung
AGB sind nicht Bestandteil eines Vertrages, wenn
- - die Vertragsparteien eine individuelle Vertragsvereinbarung getroffen haben,
- - es sich dabei um Betriebs- oder Dienstvereinbarungen, Tarifverträgen, sowie Verträge die auf Erb-, Familien- oder Gesellschaftsrecht basieren.
Sind AGB nicht Bestandteil des Vertrags bleibt der übrige Vertrag wirksam, es treten die gesetzlichen Vorschriften an deren Stelle (häufig BGB)
Äußere Form
AGB bedürfen nach § 305 Abs. 1 keiner besonderen Form, Ausgabe und Gestaltung haben keinen Einfluß auf die Gültigkeit, sie könnten sogar auf eine Serviette geschrieben werden.
Klauseln
Auch für die Klauseln und deren Inhalt gibt es keine gesetzliche Vorschriften, sofern Sienicht gegen
- die gesetzlichen Klauselverbote ohne Wertungsmöglichkeit verstoßen [§ 309 BGB] ( z. B. Verbot, die gesetzlichen Gewähleistungsfristen zu verkürzen, Pauschalisierung von Schadenersatzansprüchen, Vertragsstrafe androhen bei Nichteinhaltung der Vertragspflichten).
- die gesetzlichen Klauselverbote mit Wertungsmöglichkeit verstoßen [§ 308 BGB], (Bsp.: Änderungsvorbehalt, Rücktrittsvorbehalt, Nichtverfügbarkeit einer Leistung). Die Klausel muss durch ein Gericht geprüft werden, erst dann ist sie unwirksam.
- gegen die Gebote von Treu und Glauben verstoßen [§ 307 BGB], den Vertragspartner unangemessen benachteiligen (Gefährdung des Vertragszwecks durch Einschränkung von Rechten und Pflichten wie Ausschluss der Gewähr für Funktionsfähigkeit, intransparente Klauseln).
Überraschende oder mehrdeutige Klauseln sind auch unwirksam.
Folgen: Wenn AGB ganz oder teilweise unwirksam sind, bleibt der übrige Vertrag wirksam, es treten die gesetzlichen Vorschriften an deren Stelle (häufig BGB).
Liste üblicher Klauseln:
- - Vertragspartner (Verwender, die andere Partei)
- - Vertragsgegenstand
- - Vertragsabschluss
- - Zahlung
- - Lieferung
- - Eigentumsvorbehalt
- - Widerrufsrecht
- - Nutzungsrechte
- - Gewährleistung
- - Gerichtsstand
- Zum Verfassen von Kommentaren bitte anmelden.
U2: Kosten und Umsatz
- Zum Verfassen von Kommentaren bitte anmelden.
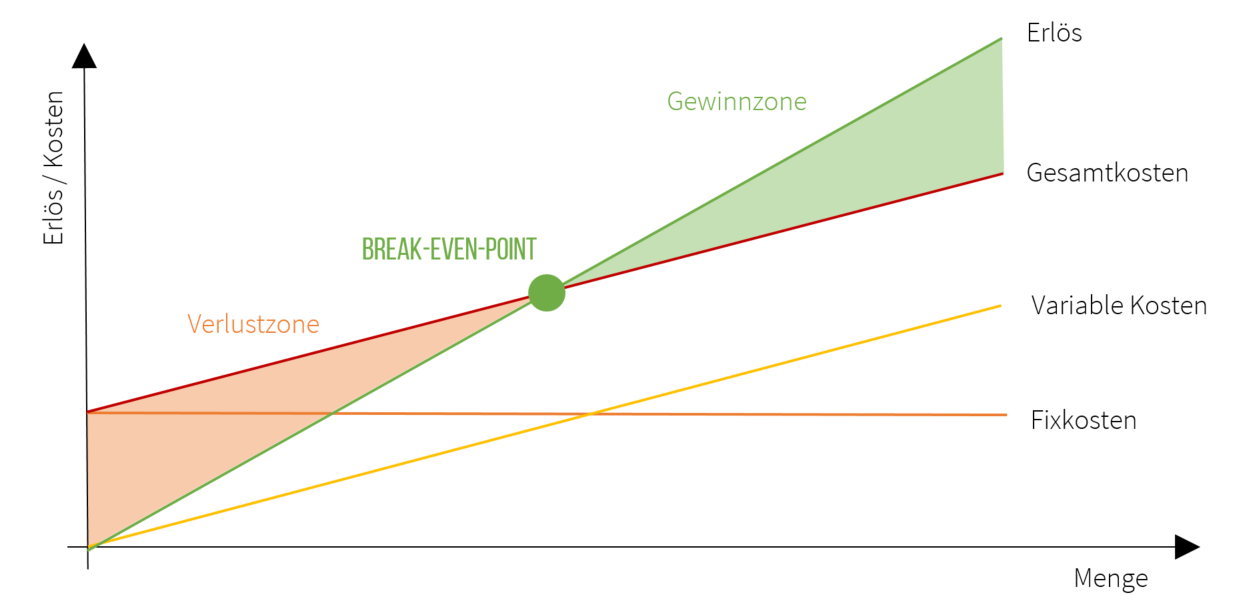
Break-Even-Point
Definition
An diesem Punkt ist der Umsatz bzw. Absatz so hoch, dass alle fixen UND variablen Kosten gedeckt sind. Jeder weitere Euro ist Gewinn.
Berechnung
1. Schritt - Deckungsbeitrag je Stück berechnen:
Verkaufspreis – variable Kosten = Stück-Deckungsbeitrag
2. Schritt - Gewinnschwellen-Menge berechnen:
Fixkosten : Stück-Deckungsbeitrag = Gewinnschwellen-Menge
- Zum Verfassen von Kommentaren bitte anmelden.
| Anhang | Größe |
|---|---|
| 79.88 KB |
{kind=link}
U3: Schriftmerkmale
- Zum Verfassen von Kommentaren bitte anmelden.
Schriftmerkmale
Buchstabenelemente
Die Merkmale sind Anstriche, Abstriche, Auslaufpunkte, Rundungen und Serifen sowie der Serifenansatz. Die genannten Merkmale geben dem Schriftbetrachter Hinweise auf die Zugehörigkeit zu einer Schriftgruppe. Die Formen der Merkmale ändern sich jedoch von Schriftgruppe zu Schriftgruppe, zum Teil sogar erheblich. Innerhalb einer Schriftgruppe sind die Unterschiede in der Regel nicht gravierend. Alle Anstriche, Abstriche, Auslaufpunkte usw., die zu einer Schrift gehören, haben die gleiche Form.
Merkmale
Schriften erkennt man an den folgenden Merkmalen, die alle auf dieser Seite aufgezeigt sind:
Dachansatz, Serifen, Grund- und Haarstriche, Symetrieachse, Querstrich des kleinen „e“, An- und
Abstriche, Auslaufpunkte.
Die wichtigsten Entwicklungsmerkmale für die folgenden Schriften:
Gotische Schriften
Aus der Schreibtechnik der schräggehaltenen Breitfeder entwickelte schmale Schriften, deren
Wortabstände minimiert werden. Schmale, gitterartige Wirkung mit geringem Zeilenabstand
beeinträchtigt die Lesbarkeit.
Renaissanceschriften
Die karolingische Minuskel wird als Vorbild wiederentdeckt. Als Versalien werden die Formen
der Capitalis Monumentalis verwendet. Diese Schriften sind heute in die Schriftgruppe der
„Renaissance-Antiqua“ eingeordnet.
Barockschriften
Es entsteht eine Handschrift-Antiqua, die wir heute alle als Kursivschrift oder als Schreibschrift
kennen. Diese Schriften weisen Zierschwünge auf und machten einen verspielten, leichten und
meist gut lesbaren Eindruck. Grund- und Haarstriche weisen Unterschiede auf und werden im Zuge einer schneller werdenden Schreibtechnik als Stilelement verwendet.
Klassizistische Schriften
Sie weisen einen starken bis extremen Wechsel von Grund- und Haarstrichen auf. Die Serifen
sind rechtwinklig an die Grundstriche angesetzt. Die Grundformen ergaben sich aus den römischen
Kapitalschriften. Deren Grundkonstruktionen wurden auf die Minuskeln übertragen. Die
Formen der Kleinbuchstaben entwickelten sich aus karolingischer oder italienischer Minuskel.
Weitere Merkmale einer Schrift
- Dickte: Buchstabenbreite+1/2 geviert Vor+Nach Buchstaben
- Duktus: Strichführung und Stärke einer Schrift, bestimmt die Gesamtanmutung einer Schrift
- Zum Verfassen von Kommentaren bitte anmelden.
U4: Tabellen
- Zum Verfassen von Kommentaren bitte anmelden.
Tabellen
Aufbau von Tabellen
Aufteilung in Spalten, Zeilen, ...
- Wie kann man eine Tabelle besser lesbar und attraktiver gestalten?
1. Spaltenbreite anpassen
Vorteil:
- Überschriften vollständig sichtbar
- besseren optischen Eindruck
2. Passende Schriftarten verwerden:
Vorteil:
-Zielgruppe(Welche?)
-klare, dezente Schriften ohne Serifen
3. Farben sparsam verwerden
Vorteil:
- Faustregel: Jede Farbe muss eine Bedeutung haben
- blasse Hintergründe (Farben) verwenden
- Dunkel-auf-Hell-Regel einhalten (beim Druck)
- Zum Verfassen von Kommentaren bitte anmelden.
Tabellensatz
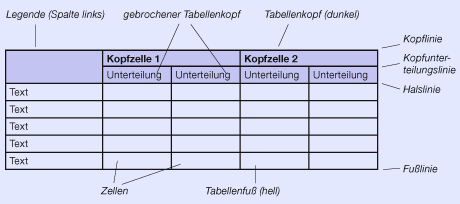
Eine Tabelle stellt Informationen, die zu einander in Beziehung gesetzt werden können, in geordneter Übersicht dar. Die linke Spalte (Legende) sowie die obere Zeile (Kopf) fungieren dabei ähnlich wie die Achsen eines Koordinatensystems. In ihnen stehen die Oberbegriffe für die Informationen der jeweiligen Spalte und Zeile, die im Tabellenfuß, dem eigentlichen Infomationsbereich, dargestellt werden.
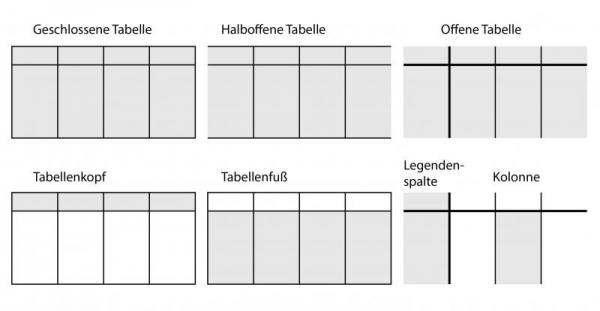
Eine Tabelle, die vollständig von einer Linie umschlossen wird, heißt geschlossene Tabelle. Fehlen die senkrechten Außenlinien, ist es eine halboffene Tabelle. Wenn sie gar nicht von eine Linie umschlossen wird, ist es eine offene Tabelle.
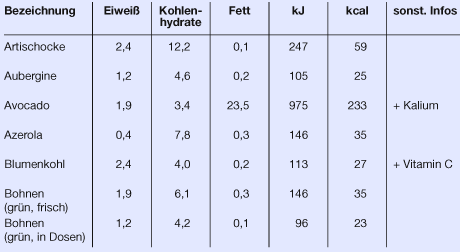
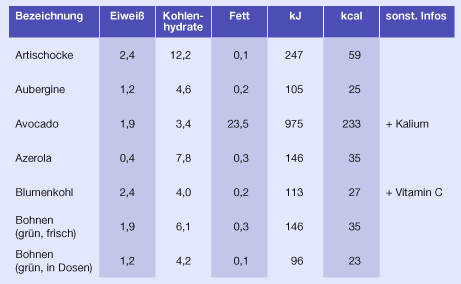
Bei der Tabellengestaltung ist es wichtig, dass gleich wichtige Informationen (im Beispiel oben die jeweiligen Nährwerte) die gleiche Spaltenbreite erhalten. Das strukturiert und beruhigt die Gestaltung. Die Spaltenbreite richtet sich nach der Information mit dem größten Platzbedarf.
Die Inhalte der Legendenspalte werden fast immer linksbündig gesetzt, damit ein einheitlicher Beginn erfolgt. Je nach Inhalt werden die Informationen der Zeilen ebenfalls linksbündig, aber auch auf Mittelachse oder ggf. rechtsbündig (wie in diesem Beispiel, damit die Einheiten untereinander stehen) gesetzt.
Ebenso muss eine einheitliche Ausrichtung für den Tabellenkopf gefunden werden. Sind die dort enthaltenen Informationen von sehr unterschiedlicher Länge wirkt es meist am ruhigsten, wenn sie auf Mittelachse gesetzt werden. Der Tabellenkopf sollte so gestaltet sein, dass er sich eindeutig vom Tabellenfuß abhebt.

Statt eine Tabelle mit Linien optisch zu gliedern, kann man auch farblich abgestufte Balken verwenden. Ob die Balken horizontal oder vertikal verlaufen, richtet sich danach, welche Informationen vergleichbar dargestellt werden sollen. In der oberen Tabelle wird der Schwerpunkt auf die jeweiligen Nahrungsmittel gelegt, in der unteren Tabelle auf die Nährwerte.
- Zum Verfassen von Kommentaren bitte anmelden.
U5: DSGVO
- Zum Verfassen von Kommentaren bitte anmelden.
DSGVO
Newsletter-Einverständnis
Dieser Unterpunkt betrifft vor allem die Digitalen unter uns. Jeder kennt Newsletter und viele Unternehmen verschicken sie, doch dürfen sie das einfach so? Welche Modelle gibt es und was für Voraussetzungen müssen erfüllt sein? Nehmt euch ein Tässchen von Babuschkas gutem Pflaumenkompott, setzt euch auf Bruder Boris' Schoß und lauscht.
1. Opt-Out Modell
Der Absender des Newsletters geht von Anfang an davon aus, dass der Empfänger diesen bekommen möchte bzw. interessiert sich gar nicht erst dafür und schickt sie munter raus. In der E-Mail steht bestenfalls irgendwo ein Link zum Deabonnieren des Newsletters, doch nach der Einverständnis, diesen überhaupt zu bekommen, wurde nie gefragt. Dieses Modell ist super unseriös und in digitaler Form seit 2005 sogar gesetzlich verboten.
2. Opt-In Modell
Der Empfänger muss noch vor dem ersten Newsletter sein Einverständnis gegeben haben. Dies kann z.B. durch ein Kontaktformular oder auch einfach nur durch hinterlegen der E-Mail-Adresse erfolgen. An sich klingt dieses Modell legitim, doch stellt euch vor der Kevin von nebenan vertippt sich bei seiner E-Mail Adresse, gibt ausversehn eure ein und PIPEZ. Auf einmal seid ihr auf der Mailing-Liste von irgendeinem furry porn Blog. Aus diesem Grund ist dieses Modell auch vor Gericht nicht standhaft, denn es gibt keine Garantie dafür, dass die E-Mail-Adresse auch vom tatsächlichen Besitzer hinterlegt wurde.
3.Double-Opt-In Modell
Noch einen Schritt weiter geht das Double-Opt-In Modell, bei dem der Empfänger sich nicht nur für einen Newsletter angemeldet haben, sondern diese Anmeldung auch aus seinem E-Mail-Postfach bestatätigt haben muss. Nachdem der potenzielle Newsletter-Empfänger seine E-Mail-Adresse hinterlegt hat, bekommt er eine E-Mail mit Bestätigungslink, um seine Identitäten zu verifizieren. So kann der Absender sichergehen, dass die Einverständnis des Empfängers gegeben ist.
Bratuhas, seid wie Boris: Schützt eure Kundendaten vor Kevins und verwendet für eure Newsletter-Anmeldung das Double-Opt-In Modell. Dieses ist zwar noch keine gesetzliche Pflicht, allerdings ist die Umsetzung nur mit einem kleinen Arbeitsaufwand verbunden und ihr seid vor Gericht sicher.
Quellen: https://www.digitale-offensive.de/glossar/opt-in-opt-out-double-opt-in/
Like, share and subscribe, hit that notification bell.
xoxo Boris
Weitere Informationen:
https://www.haufe.de/compliance/recht-politik/eu-datenschutz-grundverordnung-die-10-wichtigsten-regeln_230132_402196.html
- Zum Verfassen von Kommentaren bitte anmelden.
U6: Farbensehen
- Zum Verfassen von Kommentaren bitte anmelden.
Farbensehen – Farbmetrik
- die lichtempfindliche Struktur des Auges ist die Netzhaut
- die enthält die Photorezeptoren (Stäbchen und Zapfen) sowie verschiedenartige Nervenzellen, die sich schließlich zum Sehnerv vereinen
- die Rezeptoren wandeln als Messfühler den Lichtreiz in Erregung um
- nur die Zapfen sind farbtüchtig
- es gibt 3 verschiedene Zapfentypen, die je ein spezifisches Photopigment besitzen, dessen Lichtabsorption in einem ganz bestimmten Wellenlängenbereich ein Maximum aufweist
- diese Maxima liegen im Rotbereich bei 600 – 610 nm (Rotrezeptor), im Grünbereich bei 550 – 570 nm (Grünrezeptor) und im Blaubereich bei 450 – 470 nm (Blaurezeptor)
- durch die Überschneidung der Absorptionskurven sprechen auf viele Wellenlängen mehrere Zapfentypen in unterschiedlicher Stärke an
- jede Farbe wird durch ein für sie typisches Erregungsverhältnis der 3 Rezeptorentypen bestimmt
- die Farbvalenz ist die Bewertung eines Farbreizes durch die 3 Empfindlichkeitsfunktionen des Auges
- pathologisch können eine oder mehrere Komponenten gestört sein oder ganz fehlen – es kommt dann zu Farbsehstörungen, der Farbenschwäche oder Farbenblindheit
- diese Störungen werden durch das X-Chromosom rezessiv vererbt
Farbmetrik
- die Farbmetrik entwickelt Systeme zur quantitativen Erfassung und Kennzeichnung der Farbeindrücke (Farbvalenzen)
- das menschliche Farbensehen wird messtechnisch erfassbar und ermöglicht somit eine objektive Prozesssteuerung des gesamten Workflows
- die Normfarbwertanteile x, y und z kennzeichnen den geometrischen Farbort einer Farbe
- sie lassen sich einfach aus den Farbvalenzen errechnen
Farbseparation
- wenn es um das Drucken von Farben geht, hört man oft den Begriff Farbseparation. Dies kann mehreres bedeuten: Spotfarben, Schmuckfarben
- als Spot- oder Schmuckfarben werden Farben bezeichnet, die nicht durch Farbmischung beim Drucken erzeugt werden, sondern dadurch, dass der jeweilige Farbton beim Drucken dazugegeben wird.
- werden Spotfarben gedruckt, dann ist für jede Farbe eine separate Druckvorlage notwendig
- will man 7 verschiedene Farben, benötigt man auch 7 Filme pro Seite
- Farbseparation bedeutet hier, dass die einzelnen verwendeten Farben herausgefiltert und auf separaten Filmen belichtet werden
Vierfarbdruck
- Farbseparation bedeutet beim Vierfarbdruck, dass die verwendeten Farben in ihre Grundbestandteile zerlegt werden, so dass 4 Filme benötigt werden
- 16,7 Mio. Farbnuancen werden durch Mischen von 3 Grundfarben erzeugt
- die 4. Farbe schwarz dient zur Qualitätssteigerung
- durch ein satteres Schwarz werden Tiefen erzeugt, die durch die Mischung der 3 Grundfarben nicht erreichbar wären
- dabei müssen die einzelnen Punkte so angeordnet werden, dass kein Moiré entsteht
- Rasterweiten und Rasterwinkelungen müssen für jede Farbe unterschiedlich und sehr präzise eingestellt werden
- hier werden sehr hohe Anforderungen an alle Komponenten gestellt
- z.B. benötigt das Belichtungsstudio Belichter mit hoher Genauigkeit, die in klimatisierten Räumen stehen müssen
- auch werden für Belichtungen von Filmen für den Vierfarbdruck neue Möglichkeiten der Rasterung (z.B. andere Punktformen) entwickelt
Analytische Farbmetrik
- Normale = deskriptive (beschreibende) und analytische Farbmetrik
- die „normale“ Farbmetrik hat die Aufgabe Farben zu messen und zu beschreiben und darüber hinaus in der „höheren“ Farbmetrik auch Farbunterschiede möglichst empfindungsgemäß richtig zu bewerten. Diese Aufgaben sind zusammenfassend als deskriptive einzustufen
- die „analytische Farbmetrik“ geht der Farbe „auf den Grund“, bewertet die optischen Materialeigenschaften z.B. einer Lackfarbe in Gestalt ihrer optischen Daten, d.h. ihrer wellenlängenabhängigen Absorptions- und Streukoeffizienten
- die normale Farbmetrik bestimmt z.B. eine Farbdifferenz, die analytische klärt ihre Ursache und ermöglicht ihre Beseitigung
- während die normale, deskriptive Farbmetrik nur z.B. feststellen kann, dass zwischen 2 blauen Testaufstrichen eine Ursache dieser Farbdifferenz auf eine um 5% geringere Farbstärke zurückzuführen und die Farbdifferenz durch entsprechende Änderung der Konzentration zu beseitigen
- s/w – Kontrast – appliziert man einen Lack in nicht deckender Schicht auf schwarz-weißem Kontrastkarton so ist zwischen Schwarz und Weiß ein Kontrast – die Berechnung des Deckvermögens des Lackes anhand der optischen Daten, die aus den R-Werten über Schwarz und Weiß berechnet werden können
Farbrezeptberechnung
- mittels der optischen Daten, die sich aus den R-Werten von „Eichfärbungen“ berechnen lassen, werden die Konzentrationen von Farbmitteln berechnet, welche den gleichen Farbeindruck wie die Vorlage hervorrufen
- die analytische ermöglicht die Berechnung von Farben aus optischen Materialkonstanten
- Zum Verfassen von Kommentaren bitte anmelden.
U7: Digitale Veröffentlichung
- Zum Verfassen von Kommentaren bitte anmelden.
Digitale Veröffentlichung
Als Online-Publikationen oder Netzpublikationen bezeichnet man elektronische Publikationen, die nicht auf einem physischen Datenträger, sondern über das Internet oder ein lokales Netzwerk (z. B. in Unternehmen) angeboten werden.
Erscheinungsformen
Beispiele für Netzpublikationen sind Internet-Zeitungen, E-Mail-Newsletter, Elektronische Zeitschriften, Wikis, Weblogs, E-Books, Information Retrievals oder auch Datenbanken und allgemein Webseiten. Es darf sich jedoch nicht um reine Ansammlungen von Dateien, sondern muss sich um logische und konsistente Einheiten handeln, die sich mit Metadaten (Autor, Titel, Veröffentlichungsdatum etc.) beschreiben lassen. Unabhängig davon lassen sich auch andere im Internet verfügbare Daten als publiziert bezeichnen.
Unterschieden wird dabei zwischen webspezifischen Netzpublikationen mit typischen Eigenschaften von Webseiten wie Suchfeldern, Links oder auch Datenbanken einerseits und druckbildähnlichen Publikationen andererseits, die dem „look and feel“ eines gedruckten Artikels entsprechen. Letztere werden im Internet meist in Form einer Datei im Portable Document Format (PDF) veröffentlicht.
Archivierung
Aufgrund der Flüchtigkeit des Mediums und des schnellen technischen Wandels ist das Problem der Langzeitarchivierung ungelöst. Grundsätzlich lassen sich zwei Kategorien von Lösungsansätzen unterscheiden. Zum einen wird das Netz bzw. Teile davon mit Hilfe von Software automatisiert archiviert (z. B. Internet Archive), zum anderen werden die Netzpublikationen von den Verlegern aktiv in einem Archiv abgelegt. Beispielsweise trat in Deutschland am 29. Juni 2006 das „Gesetz über die Deutsche Nationalbibliothek“ in Kraft, durch das der Aufgabenbereich der Deutschen Nationalbibliothek auf das Archivieren von Netzpublikationen ausgedehnt wurde. Da mit den URIs (URI: Uniform Resource Identifier) die Ressource der Netzpublikationen identifiziert wird, nicht aber die Netzpublikation selbst, und der langfristige Bestand einer URI im Allgemeinen nicht sichergestellt werden kann, stellt sich die Herausforderung, die Netzpublikation selbst (eindeutig und dauerhaft) zu identifizieren. Aufbauend auf dem ISBN-System der klassischen Buchpublikationen haben sich dabei der vornehmlich kommerziell genutzte Digital Object Identifier (DOI) sowie der nichtkommerzielle Society Reference Catalogue (SRef) etabliert, desgleichen der Persistent Uniform Resource Locator (PURL) und der Uniform Resource Name (URN) als weitere persistent identifier.
Impressumspflicht
Ein weiteres Problem, das sich bei Netzpublikationen stärker als bei herkömmlichen Publikationen stellt, ist, dass sich ihre Herausgeber und Urheber nicht immer einfach feststellen lassen. In Deutschland müssen Websites deshalb analog zum Impressum gemäß Telemediengesetz eine verantwortliche Person benennen und weitere Angaben machen.
Personalisierter Zugang
Für die Nutzung kommerzieller Netzpublikationen, wie beispielsweise Elektronische Zeitschriften und Datenbanken, wird in der Regel ein Benutzerkonto (Account) benötigt, über das anfallende Kosten abgerechnet werden. Die Zugangskontrolle kann über ein Kennwort und eine Beschränkung von IP-Adressen erreicht werden.
- Zum Verfassen von Kommentaren bitte anmelden.
U8: Datenbank-Entwurf
- Zum Verfassen von Kommentaren bitte anmelden.
Datenbanken (Normalisierung)
Spricht man von einer Datenbank, meint man in der Regel ein Datenbanksystem (DBS). Dieses besteht aus zwei Teilen: Die eigentliche Datenbank (DB) ist eine programmunabhängige strukturierte Sammlung von Daten, die miteinander in Beziehung stehen. Um diese Daten sinnvoll und komfortabel nutzen zu können, wird eine Datenbanksoftware benötigt, das Datenbankmanagementsystem (DBMS).
Ziele einer Datenbank:
- Vereinheitlichung: Daten werden nur einmal erfasst und zentral gespeichert, sodass allen Benutzern eine einheitliche und aktuelle Datenbasis zur Verfügung steht.
- Flexibilität: Die erfassten Daten lassen sich mehrfach und unterschiedlich nutzen und auswerten.
- Programmunabhängigkeit der Daten: Wird durch die Trennung von DB und DBMS erreicht.
- Fehlerfreiheit: Datenbankfehler, die z.B. durch einen Programm- oder Computerabsturz entstehen, sollen automatisch korrigiert werden.
-Redundanz-Vermeidung: Unter Redundanz versteht man eine doppelte oder mehrfache Speicherung gleicher Daten. Dies führt zu Speicherplatzverschwendung, erhöht die Verarbeitungszeiten und kann zu widersprüchlichen Daten führen.
Folgende Kriterien für eine funktionierende Datenbank müssen erfüllt sein:
Datenkonsistenz: Jeder Datensatz muss eindeutig identifizierbar, also konsistent sein, z.B. werden Kundennummern nur ein einziges Mal vergeben. Wenn der Kunde nicht mehr existiert, wird die Nummer nicht erneut verwendet. Somit sind konsistente Datensätze eindeutig unterscheidbar.
Beispiel: Selbst bei dem unwahrscheinlichen Fall, dass zwei Kunden dieselbe Adresse haben, kann mindestens durch die einmalig vergebene Kundennummer zwischen ihnen unterschieden werden.
Redundanzfreiheit: Sämtliche Daten werden nur einmal erfasst und gespeichert (=sie sind redundanzfrei). So treten bei Änderungen keine Probleme auf, da sie zentral abgelegt sind und nur ein Mal geändert werden müssen.
Beispiel: Ändert sich bei einem Kunden die Adresse, muss diese nicht für jede seiner Bestellungen erfasst und geändert werden, sondern nur ein Mal zentral in der Kundendatenbank, da den Bestellungen die eindeutige Kundennummer zugeordnet ist. Somit dient diese Nummer als Schlüssel.
Normalformen
1. Normalform: Jedes Datenfeld einer Tabelle enthält genau einen Eintrag, diese sind spaltenweise sortiert, z.B. nach Nachname, Straße, PLZ, Ort, Produkt und Datum. In der Tabelle der 1. NF sind alle Informationen gelistet, daher ist sie nicht konsistent und nicht redundanzfrei.
Beispiel: Der Kunde Winkler hat Visitenkarten und eine Website in Auftrag gegeben. Da ja jedes Datenfeld nur einen Eintrag enthält, ist der Kunde zwei Mal in der Auftragstabelle aufgeführt, ein Mal mit dem Produkt Website mit der Auftragsnummer 1 und ein Mal mit dem Produkt Visitenkarten mit der Auftragsnummer 5. Diese Nummern verweisen auf den Kunden und auf das Produkt.
2. Normalform: Nun wird die Tabelle in mehrere Tabellen zerlegt und zwar so, dass jeder Eintrag der entstandenen Tabellen einen eigenen Schlüssel erhält. Dieser Schlüssel wird dann anstatt des Produktes in der Tabelle der 1. NF aufgeführt. So befindet sich die Auftragstabelle in der 2. NF, da sie sich zum einen in der 1. NF befindet und zum anderen alle Datenfelder von einem Schlüssel funktional abhängig sind.
Beispiel: Die Produkte werden in einer eigenen Tabelle aufgeführt und jedes Produkt erhält eine Produktnummer (Schlüssel). So wird in der Auftragstabelle nun nicht das Produkt mit Namen angegeben, sondern der Schlüssel. Somit ist der Kunde Winkler zwar immernoch zwei Mal in der Auftragstabelle aufgeführt, jedoch ein Mal mit der Produktnummer 1 für die Website und ein Mal mit der Produktnummer 2 für Visitenkarten. Die Produktnummer 2 kann in der Tabelle natürlich ebenfalls für den Kunden Mayer vorkommen, der ebenfalls Visitenkarten in Auftrag gegeben hat.
3. Normalform: In dieser letzten Stufe werden die verbliebenen Redundanzen beseitigt. Die endgültige Tabelle befindet sich dann in der 3. NF, wenn sie sich zum einen in der 2. NF befindet und zum anderen alle Datenfelder, die keine Schlüssel sind (im Bsp. das Auftragsdatum), nicht funktional abhängig sind.
Beispiel: Nun sind die Kundenangaben in der Auftragstabelle funktional abhängig, also zum Kunden Winkler gehört genau eine Straße, eine PLZ und ein Ort. Das muss nun behoben werden, da ein weiterer Kunde namens Winkler hinzukommen kann und sich dadurch die Adresse anhand des Namens nicht mehr eindeutig ermitteln ließe. Deshalb wird eine weitere Tabelle mit neuem Schlüssel erstellt. Hier befinden sich die Daten der Kunden, die spaltenweise nach Name, Straße, PLZ und Ort aufgeführt sind. Das Wichtigste ist nun, dass jeder Kunde eine Kundennummer (Schlüssel) erhält, der in der Auftragstabelle angegeben werden kann. Diese Tabelle wird kann nun in die 3. NF gebracht werden: Eine Spalte gibt die Auftragsnummer an, eine die zugehörige Produktnummer, eine Spalte führt die Nummer des zugehörigen Kunden auf und eine weitere Spalte kann nun das Datum des Auftrags enthalten.
Nun ist die Normalisierung in die 3. NF abgeschlossen, alle Daten der 3 Tabellen sind redundanzfrei und konsistent.
Weiterführende Links
http://www.tinohempel.de/info/info/datenbank/normalisierung.htm
- Zum Verfassen von Kommentaren bitte anmelden.
U9: Logogestaltung
- Zum Verfassen von Kommentaren bitte anmelden.