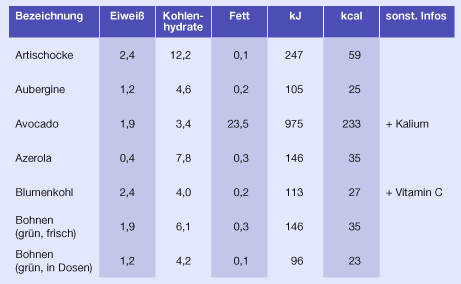
Definition: Der Aufdruck von Text und Bild auf dem Druckbogen muss vor dem Falzen erfolgen. Die Anordnung der Einzelseiten mit Text und/oder Bild innerhalb der gesamten Druckform muss also so erfolgen, dass nach dem Bedrucken, Falzen und Zusammenführen der Bogen eine fortlaufende Seitenzahl zustande kommt. Die Anordnung der Einzelseiten für die Druckform wird Ausschießen genannt.
Reihenfolge beim Ausschießvorgang:
Erstellen eines Falzmusters
Erstellen eines Ausschießschemas mit dem Falzmuster als Grundlage
Erstellen des Einteilungsbogens
Druck des Standbogens (als das Ausschießen noch manuell gemacht wurde)
Unterschied von Einteilungsbogen und Falzbogen
Schaut man in der einschlägigen Fachliteratur beim Thema Ausschießen nach, ist man unter Umständen verwirrt. Im Kompendium (3. und 4. Ausgabe) heißt es zum Beispiel:
»Die erste und alle übrigen Seiten mit ungeraden Zahlen stehen immer links vom Bund. Alle Seiten mit geraden Ziffern stehen rechts vom Bund.«
Im dem Buch "Falz- und Ausschießpraxis" (Verlag Beruf + Schule) steht jedoch in den Auschießregeln, dass gerade Seitenzahlen in den Bund, ungerade aus dem Bund gelesen werden. Auch wenn man sich eine gedruckte Broschüre anschaut, denkt man doch, dass das, was im Kompendium drin steht, falsch wäre. Denn die erste Seite in einer Broschüre ist immer rechts und damit auch die anderen ungeraden Seitenzahlen. So kennt der Buchbinder zum Beispiel auch den Falzbogen.
Bei der manuellen Montage arbeitete man jedoch beim Erstellen des Einteilungsbogens je nach Druckverfahren seitenverkehrt, so dass die Anordnung im Ausschießschema seitenverkehrt zu der im Falzbogen/Endprodukt ist. Es ist verwirrend, aber soweit korrekt.
Heute wird der Einteilungsbogen digital erstellt und ist seitenrichtig!
Der Einteilungsbogen
Der Einteilungsbogen ist die Vorlage für die genaue Platzierung von Texten und Bildern bei der Montage. Er enthält Angaben für Druck und Weiterverarbeitung.
Elemente: Bogenformat, Nutenformat, Druckbeginn, Greifrand, Beschnitt Mittelsenkrechte, Schneidemarken, Falzmarken, Passkreuze, Satzspiegel, Seitenzahl, Flattermarken, Anlagezeichen, Druckkontrollstreifen
Stege: Zu unterscheiden sind zwei Formen von Stegen die nicht vertauscht werden sollten:
- Formatstege: Der Begriff stammt auf dem Buchdruck. Die Leerräume zwischen den Seiten wurden mit "Formatstegen" festgelegt (u.a. Mittelsteg, Kreuzsteg, Bundsteg, Kopfsteg).
- Stege die im Seitenformat liegen: Das Seitenformat jeder Seite umfasst den Satzspiegel sowie Kopfsteg, Außensteg, Fußsteg und Bundsteg
Erstellen des Einteilungsbogens vor der Digitalisierung
Es wurden für jeden beidseitig bedruckten Bogen zwei Einteilungsbögen (oft auf Transparentpapier) gezeichnet und auf dem Leuchttisch befestigt.
- Zuerst wurde der Einteilungsbogen für die Schöndruckseite erstellt. Die Seiten wurden hier als Umriss eingezeichnet. Beim Tiefdruck und Offsetdruck waren sie spiegelverkehrt einzuzeichnen.
- Jetzt wo die Position und Lage der Seiten auf der Schöndruckseite klar war, wurde der Einteilungsbogen für die Widerdruckseite erstellt. Hierbei war/ist die Wendeart zu berücksichtigen.
Ausschießregeln
- Die erste und die letzte Seite eines Bogens stehen im Bund immer zusammen, z.B. Seite 1 und Seite 16. Damit gilt für alle anderen Seiten, die im Bund nebeneinander stehen, dass die Seitenzahlen zusammengerechnet, die Anzahl der Seiten des Bogens plus 1 ergeben müssen.
- Der letzte Falz liegt immer im Bund.
- Bei 8 Seiten Hochformat ist die Falzanlage bei den Seiten 3 und 4
Bei 16 Seiten Hochformat und 32 Seiten Querformat ist die Falzanlage bei den Seiten 5 und 6 (bei 32 Seiten Querformat nur beim Deutschen Vierbruch der Fall)
Wendearten
Umschlagen: Vorderanlage oder -marke bleibt, Seitenanlage oder -marke wechselt. Der Bogen muss an zwei Seiten beschnitten werden, damit die Rechtwinkligkeit gegeben ist
Umstülpen: Vorderanlage wechselt, Seitenanlage bleibt. Der Bogen muss an drei Seiten beschnitten werden, damit die Rechtwinkligkeit gegeben ist
Umdrehen: Vorderanlage wechselt, Seitenanlage wechselt. Der Bogen muss an allen Seiten beschnitten werden, damit die Rechtwinkligkeit gegeben ist.
Falzmuster
Ein Falzmuster wird meist zur Kontrolle verwendet. Häufig wird es auch dazu verwendet, um sich ein erstes Bild zu verschaffen, wenn extern ausgeschossen wird. Wichtig ist, dass unten rechts die Seiten offen sind.
Ergänzend:
Beim Zusammentragen werden Einzelseiten oder Falzbogen aufeinander gelegt, beim Sammeln werden die Falzbogen ineinander gelegt. Dabei muss beachtet werden, dass die Seiten des Produkts mit zunehmender Bogenanzahl immer weiter nach außen rutschen. Überstehende Ränder werden in der Weiterverarbeitung glatt geschnitten, aber den Stand des Satzspiegels muss man vorher immer weiter anpassen.
Für die Einteilungsbogen lassen sich die ensprechenden Seiten berechnen. Also welche Seite des Produkts auf welchem Bogen liegt.
Die Formeln für das Zusammentragen:
1. Seite auf dem aktuellen Bogen = vorherige Bogenzahl x Seiten auf einem Bogen + 1
letzte Seite auf dem aktuellen Bogen = aktuelle Bogenzahl x Seiten auf einem Bogen
Bsp.: Hergestellt wird ein 32-Seiter, 8 Seiten je Bogen
Berechnung für den 3. Bogen
1. Seite auf dem 3. Bogen = 2 x 8 + 1 = 17
letzte Seite auf dem 3. Bogen = 3 x 8 = 24
17 18 19 20 Schöndruck
21 22 23 24 Widerdruck
Formeln für das Sammeln:
1. Seite auf der 1. Hälfe des aktuellen Bogens = vorherige Bogenzahl x Seiten auf einer Bogenhälfte + 1
letzte Seite auf der 1. Hälfe des aktuellen Bogens = aktuelle Bogenzahl x Seiten auf einer Bogenhäfte
1. Seite auf der 2. Hälfe des aktuellen Bogens = Gesamtseitenzahl - (letze Seite der 1. Hälfte des Bogens - 1)
letzte Seite der 2. Hälfte des aktuellen Bogens = Gesamtseitenzahl - (erste Seite der 1. Hlfte des Bogens - 1)
Bsp.: Hergestellt wird ein 32-Seiter, 8 Seiten je Bogen
Berechnung für den 3. Bogen
1. Seite auf der 1. Hälfe des 3, Bogens = 2 x 4 + 1 = 9
letzte Seite auf der 1. Hälfe des 3. Bogens = 3 x 4 = 12
1. Seite auf der 2. Hälfe des 3. Bogens = 32 - (12 - 1) = 21
letzte Seite auf der 2. Hälfte des 3. Bogens = 32 - (9 - 1) = 24
9 10 11 12 Schöndruck
21 22 23 24 Widerdruck




















{kind=link}
{kind=link}